Scraping adalah salah satu teknik penting dalam dunia data digital. Dengan scraping, kita bisa mengambil informasi dari berbagai situs secara otomatis. Tapi, teknik ini juga punya batasan dan aturan hukum yang perlu WiseSob pahami sebelum menggunakannya.
Scraping Adalah…
Scraping adalah proses pengambilan data secara otomatis dari sebuah situs web, biasanya dilakukan oleh program atau bot yang meniru cara manusia membuka dan membaca halaman tersebut. Nama lain dari teknik ini adalah web scraping atau data scraping.
Tujuan utama scraping adalah mengekstrak informasi dari halaman web dan mengubahnya menjadi format yang bisa diolah, seperti CSV, Excel, atau langsung disimpan ke dalam database. Misalnya, seorang analis harga mungkin ingin mengumpulkan daftar harga dari ratusan produk di berbagai toko online—tentu akan merepotkan jika dilakukan manual, maka di sinilah scraping membantu.
Cara Kerja Scraping: Sederhana Tapi Efektif
Konsep scraping sebenarnya cukup sederhana, yaitu:
- Membuka halaman web target menggunakan permintaan HTTP (GET)
- Mengambil struktur HTML dari halaman tersebut
- Mencari dan mengekstrak elemen tertentu (judul, harga, rating, dsb.) menggunakan selector
- Menyimpan data hasil ekstraksi ke dalam format yang diinginkan
Analogi sederhananya seperti ini: bayangkan WiseSob membuka halaman website toko online, lalu menyalin informasi nama produk dan harganya satu per satu ke Excel. Scraping melakukannya secara otomatis dan jauh lebih cepat.
Biasanya scraping dilakukan menggunakan bahasa pemrograman seperti Python, dengan bantuan pustaka seperti BeautifulSoup atau Scrapy. Untuk halaman yang kompleks dan berbasis JavaScript, tools seperti Puppeteer atau Selenium digunakan agar mampu menunggu konten dimuat secara penuh sebelum pengambilan data.
Apa Tujuan Melakukan Scraping?
Scraping digunakan di banyak bidang dan industri. Berikut ini adalah beberapa contohnya:
- Riset Harga Kompetitor: Toko online dapat mengambil data harga dari pesaing untuk menyesuaikan strategi penetapan harga mereka.
- Listing Properti: Agen properti atau agregator bisa mengambil data dari banyak situs untuk ditampilkan dalam satu platform.
- Data Produk dan Review: Platform afiliasi atau komparasi produk sering mengumpulkan informasi deskripsi, rating, dan review secara otomatis.
- Riset Akademik: Peneliti bisa mengumpulkan data dari publikasi atau forum diskusi untuk analisis sentimen atau topik tertentu.
- SEO dan Konten: Mengambil meta data atau struktur konten untuk analisis kompetitor secara legal.
Namun perlu diingat, tidak semua scraping diperbolehkan. Selalu pastikan bahwa data yang diambil memang tersedia untuk umum dan tidak dilindungi oleh ketentuan penggunaan situs tersebut.
Legalitas Scraping: Apakah Boleh?
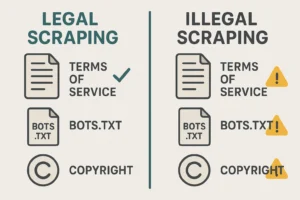
Scraping memang teknisnya mudah dilakukan, tetapi aspek hukumnya bisa rumit. Tidak semua data yang bisa diakses boleh diambil sesuka hati. Inilah beberapa hal yang perlu WiseSob pahami:
- Scraping Legal: Dilakukan pada data yang terbuka untuk umum (public data), tidak memerlukan login, dan tidak melanggar terms of service. Contoh: mengumpulkan berita dari situs media yang tidak mengatur larangan scraping.
- Scraping Ilegal: Mengambil data dari situs yang membutuhkan login, melewati sistem CAPTCHA, atau melanggar batasan pada
robots.txt. Bisa dianggap pelanggaran hukum, tergantung negara dan konteksnya.
Kasus paling terkenal adalah LinkedIn vs HiQ Labs, di mana LinkedIn menggugat perusahaan yang mengambil data profil publik mereka secara massal. Meski pengadilan sempat menyatakan scraping atas data publik tidak melanggar CFAA (Computer Fraud and Abuse Act), kasus ini menunjukkan bahwa scraping bisa jadi arena hukum yang berisiko.
Untuk amannya, selalu baca kebijakan penggunaan situs dan gunakan scraping hanya untuk tujuan etis dan sah.
Tools dan Bahasa Pemrograman Populer untuk Scraping
| Tools / Bahasa | Keterangan |
|---|---|
| Python (BeautifulSoup, Scrapy) | Pustaka populer untuk web scraping, cocok untuk pemula hingga mahir |
| Puppeteer | Berbasis Node.js, efektif untuk scraping situs berbasis JavaScript |
| Octoparse | Tool visual tanpa coding, cocok untuk pengguna non-programmer |
| Apify | Platform cloud-based yang mendukung scraping skala besar |
| Selenium | Digunakan untuk simulasi interaksi dengan browser, bisa scraping sekaligus testing |
Masing-masing tool memiliki kelebihan tersendiri. Untuk kebutuhan cepat dan ringan, BeautifulSoup bisa jadi pilihan. Untuk situs interaktif dengan JavaScript berat, gunakan Puppeteer atau Selenium.
Tips Aman dan Etis Saat Melakukan Scraping
Supaya scraping kamu tidak dianggap spam atau tindakan ilegal, ikuti tips berikut:
- Baca
robots.txt: Setiap website biasanya punya file ini yang menunjukkan bagian mana saja yang boleh dan tidak boleh diakses oleh bot. - Gunakan Rate Limiting: Batasi jumlah permintaan agar tidak membebani server. Gunakan jeda antar permintaan.
- Jangan Ambil Data Pribadi: Hindari scraping informasi pribadi seperti email atau nomor telepon tanpa izin.
- Gunakan User-Agent Jelas: Sertakan informasi siapa kamu dan tujuan scraping dalam header User-Agent.
- Simpan Cache Data: Hindari permintaan berulang ke data yang sama agar tidak over-request.
Scraping yang etis tidak hanya melindungi kamu dari konsekuensi hukum, tapi juga menjaga ekosistem internet tetap sehat.
Alternatif Legal: Gunakan API Resmi
Banyak platform modern menyediakan API sebagai alternatif legal dari scraping. API (Application Programming Interface) memungkinkan aplikasi untuk mengambil data secara terstruktur, sah, dan efisien.
Contoh API populer:
- Twitter API: Mengakses tweet publik, follower, dan tren
- Google Maps API: Mendapatkan informasi lokasi dan navigasi
- Spotify API: Data lagu, playlist, dan metadata musik
Keuntungan API dibanding scraping:
- Lebih stabil dan cepat
- Dokumentasi lengkap
- Lebih hemat resource
- Aman dan legal
Jika kamu menjalankan aplikasi yang bergantung pada data pihak ketiga, sebaiknya gunakan API resmi daripada scraping manual.
Kapan Scraping Perlu Dihindari?
Scraping tidak selalu ideal. Berikut ini situasi di mana scraping sebaiknya dihindari:
- Data Dilindungi Login: Jika data hanya bisa diakses setelah login, biasanya dilindungi oleh hak akses dan ToS.
- CAPTCHA atau Proteksi Bot: Situs dengan sistem anti-bot seperti Cloudflare atau CAPTCHA akan memblok scraping otomatis.
- ToS Melarang Scraping: Beberapa situs menyatakan jelas bahwa scraping dilarang. Jika dilanggar, bisa berakibat banned atau tuntutan hukum.
- Beban Server Berlebihan: Scraping masif dan cepat dapat membuat situs target down, ini jelas tidak etis.
Ingat WiseSob, jangan sampai scraping kamu malah mengganggu layanan orang lain. Bijaklah dalam penggunaan teknik ini.
Kesimpulan
Scraping adalah teknik powerful untuk mengumpulkan data, tapi juga perlu dilakukan secara bertanggung jawab. Gunakan hanya saat dibolehkan, dan pertimbangkan etika serta hukum saat mengakses data dari internet.
